ARLIS’s origins as a UARC were focused on comprehensive language preparedness for the DoD and the IC, particularly in the aftermath of the September 11 terrorist attacks. Then known as the Center for Advanced Study of Language (CASL), the organization assembled a stronghold of top-quality language, culture, and human performance researchers capable of responding to immediate operational requirements while still pursuing the strategic research needs of the government.
Due, in part, to this history, language research has always been a critical enabler for ARLIS mission areas, including cognitive security, insider risk, performance augmentation, and other problem spaces where data remains unstructured, multilingual, and derived from social media. Beyond our work in human language technologies, our linguists and language experts are directly involved in many of ARLIS’s current projects, along with the direct generation of high-quality data resources for government and research communities.
Communication is a crucial way to interpret disinformation campaigns and understand how the global population interacts with computer systems. For example, a cross-disciplinary team of ARLIS researchers combined their expertise in Russian language, psychology and cognitive sciences, and computational linguistics on a ground-breaking project classifying an author’s personality traits in Russian social media content. Additional social media projects are gaining new insights into how emotions influence the resharing of content on Eastern European social media, tracking Chinese influence in Kenya as part of its Belt and Road Initiative, and investigating the spread of disinformation related to the COVID-19 pandemic
Dataset Provisioning
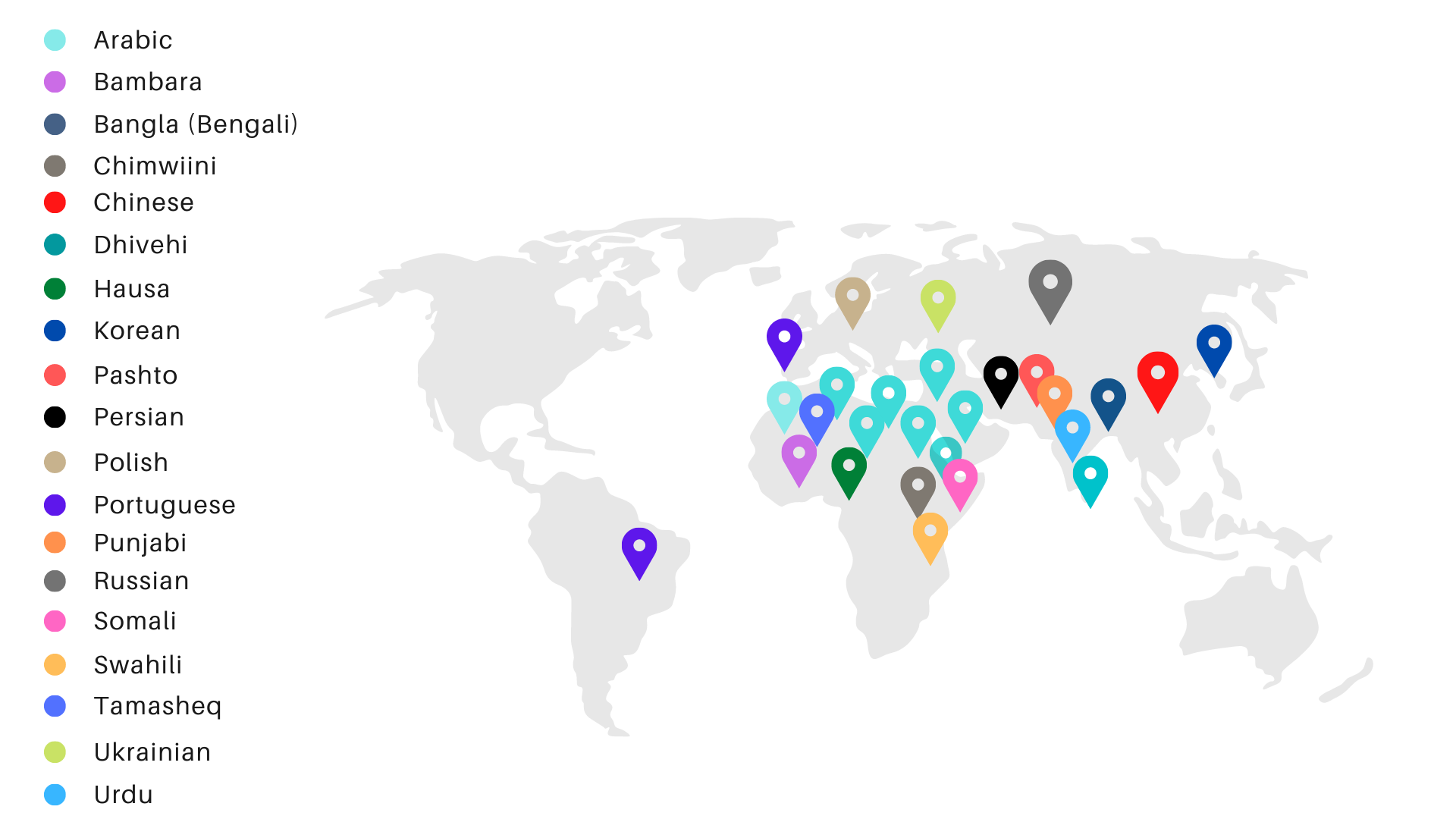
ARLIS maintains the curation of high-quality, purpose-built language datasets. Specializing in under-resourced world languages, our scientists can craft research projects that involve any human language on earth. We combine traditional and cutting-edge language data collection methods and utilize automated processes to facilitate, rather than replace expert human curation. Over its history, ARLIS (and CASL before it) has curated, normalized, and annotated linguistic data in a multitude of languages for our government clients for a broad range of analytic purposes. This research includes the fundamental resource development for unfamiliar languages and the analysis of rhetorical constructions, annotation, and multilingual social media data. These datasets have facilitated and upgraded the development of speech-to-text, text-to-speech, automatic speech recognition, machine translation, translation memory, cross-language information retrieval, reference-tracking, emotion detection, sentiment analysis, personality classification, authorship attribution, and a range of other data analytics, as well as language identification and high-level language learning.